图床和cdn代理
最近对博客的进行了一些修复,首先是对pinghsu主题进行了小更改,删除掉了页脚的信息,然后修改了一下归档页面.更喜欢这种线性的时间排列.
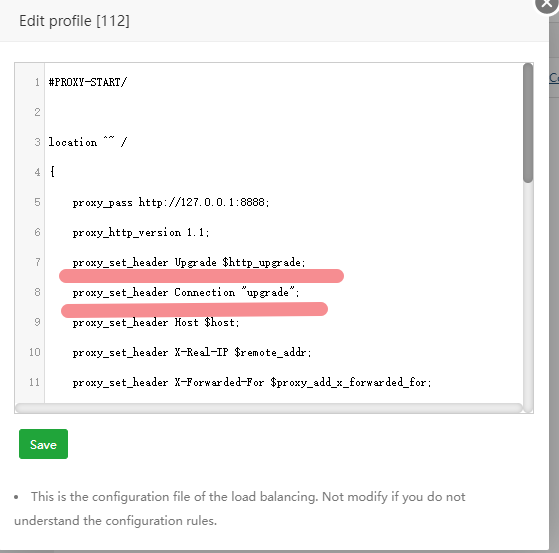
在修整完了博客页面之后,我开始对写文章的过程进行一些思考和改进.之前的写作方式是,直接在typecho后台,进行编辑写作.其他还好,只有图片这一块,在网站上编写确实不够方便.我希望能够达成的效果是一键截图,压缩,上传,再粘贴.多方搜索之后[^1],最终,确定了:VScode+PicGo+snipaste的完美组合.
markdown+VScode
首先,typecho是支持markdown的,而什么是markdown呢.
Markdown是一种轻量级标记语言,创始人为约翰·格鲁伯。它允许人们使用易读易写的纯文本格式编写文档,然后转换成有效的XHTML文档。这种语言吸收了很多在电子邮件中已有的纯文本标记的特性
简单而言就是通过一些#!符号将文章的呈现初一些段落,标题,而之前实现这个需要用word才能实现.而为了满足截图,上传一体化的操作,我选择了传说中的All in one 的VScode.
VScode作为一个IDE,他不仅可以用来编程,也可以用来编写markdown语句,只要下载一个插件:markdown All in One
然后创建文档的时候,把后缀名改为.md即可.系统自动识别为markdown文档.而且由于我不喜欢大小写转换,所以一般都是直接全部小写,等到了写完,再使用VScode自带的更改匹配项,直接全部改正.方便轻松.
snipaste
在解决完写作平台之后,我们就要实现一个截图,压缩的问题.一般而言我的图片都是直接当场截图的,所以这边推荐一个神器:snipaste[^2].这是一款桌面截图软件,而且支持特定格式输出,同时自带压缩.所以我们可以直接截图之后再让它自动压缩,达到我们压缩图片的目的.
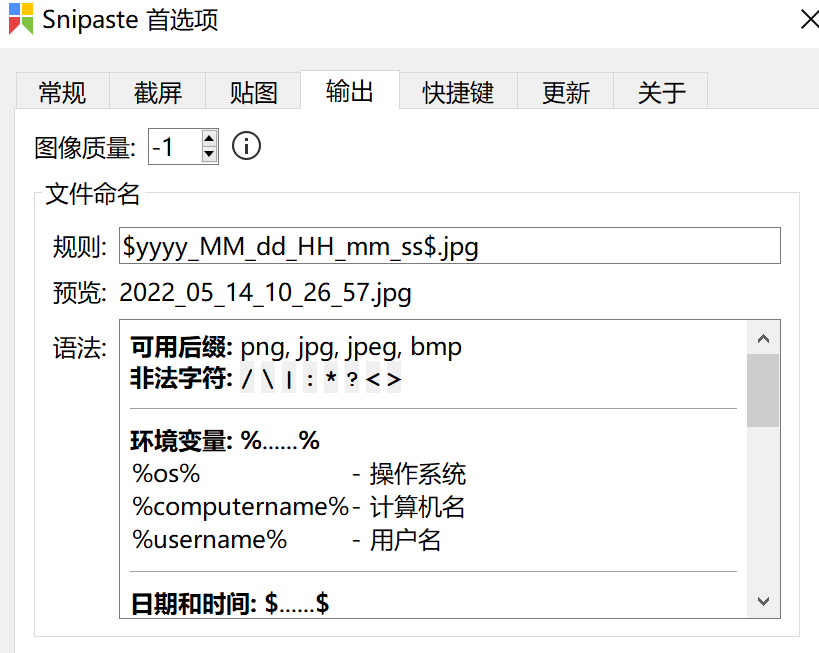
这边几个参数仅供参考,图片质量测试过:让系统自动选择和自己手动设置到压缩80%是一样的.然后后缀格式建议使用.jpg,同一个截图界面.png会比.jpg高一半以上.至于其他的格式并没有测试过.
PicGo+GitHub自建图床
在图片截图之后,我们就要上传图床然后插入链接.图床服务简单而言就是将图片存储在别的地方,然后通过网络加载.这样做有两个好处:
-
我们无需将图片保存在本地服务器,减轻了存储的压力
-
后续维护方便,图片和文章不在同一个地方,哪怕后续更换图床,只需要打包下载,再上传到别的图床即可.
而PicGo就是这么一个将你的图片上传然后再返回对应链接得一个过程.这边推荐使用得是GitHub图床.国内的直接不考虑,需要域名备案.国外得有SMMS,ImgURL,两者都有容量和大小的限制.而GitHub本质上是一个代码仓库,所以没有容量和大小的限制.唯一得问题也许就是国内访问不能.但是我们可以使用cdn加速解决.
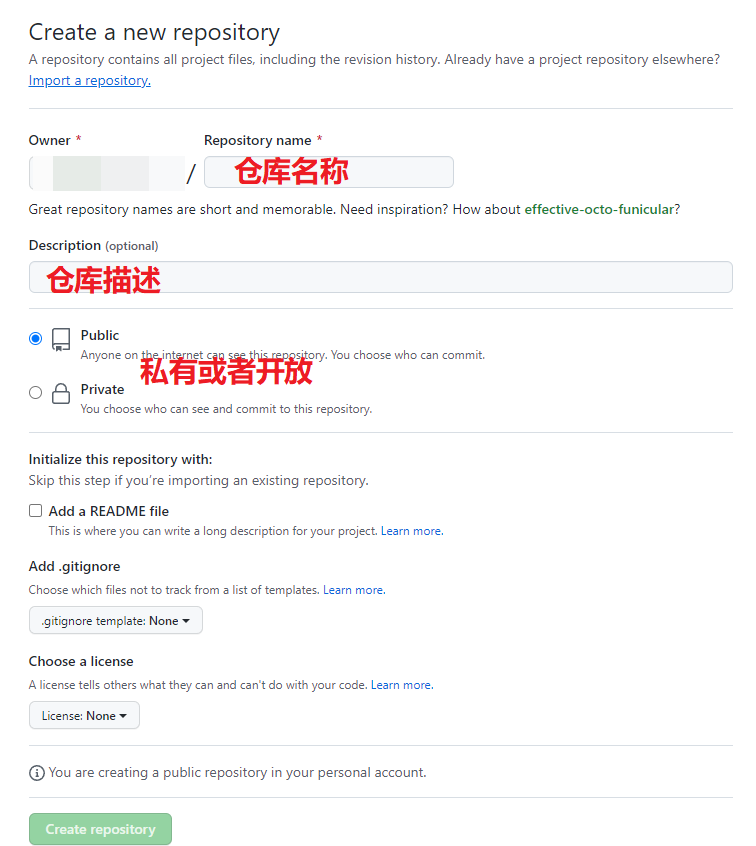
首先注册一个GitHub账号,然后创建一个仓库,私有和开放得都可以.
获取tokens,这是一串代码,运行使用这串代码得人操作你的仓库数据,我们需要给PicGo申请一个,让它可以将图片上传到我们仓库内.
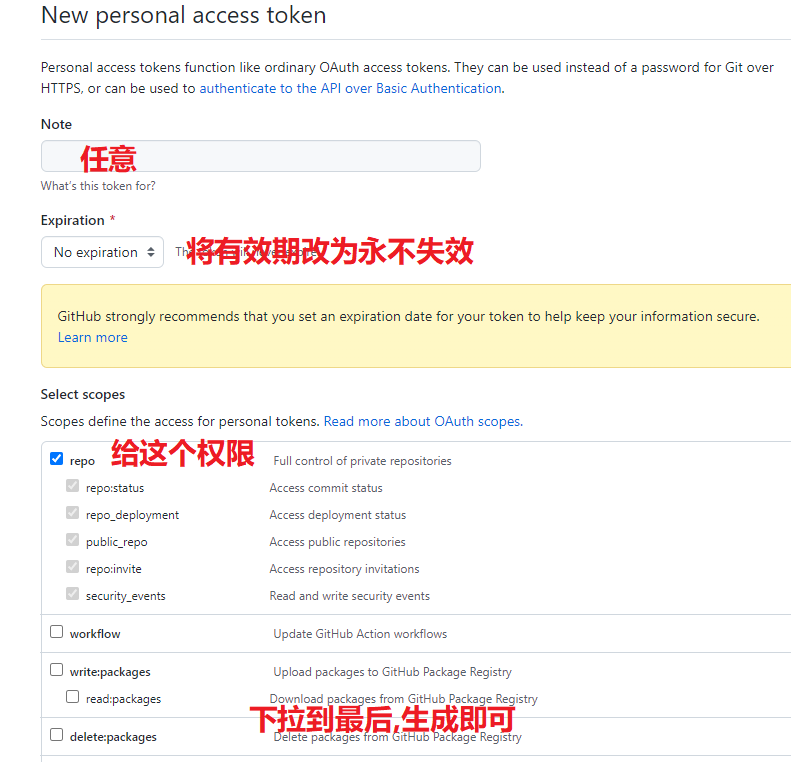
生成后你会获得一串代码,请记住,这串代码只显示一次.
然后进入VScode下载拓展PicGo:官方出品,保质保量.
进入拓展设置:
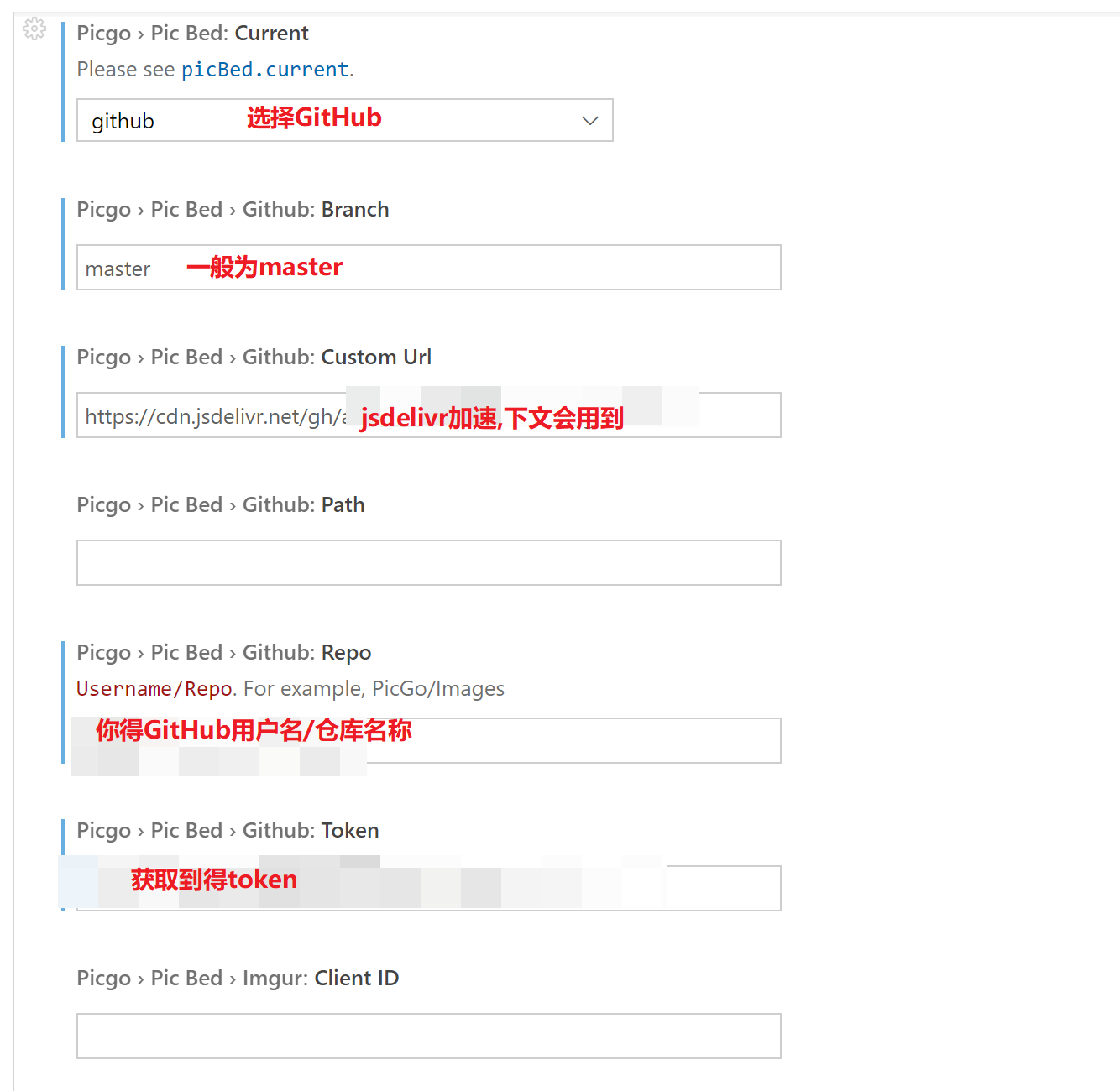
这样配置之后,你可以使用Ctrl+Alt+u把剪贴板内得图片上传,或者使用Ctrl+Alt+e打开文件管理器,选择图片上传.前者搭配snipaste,可以快速得将我们得截图上传到仓库.
jsdelivr的cdn加速
GitHub好用但是有时候国内访问艰难,所以我们需要给他cdn加速,操作方法很简单,直接再PicGo得custom url下填入:
https://cdn.jsdelivr.net/gh/用户名/仓库@master/
即可.其中master代表得是branch分支,你配置写master得话,这里也要.然后你就会发现你插入得图片链接变为了cdn加速后得链接.
完整的写作流程
经过以上一系列得配置,后续写作流程就变成再VScode上写,然后再复制粘贴到网页后台.其中图片会保存再GitHub仓库,而且内部得图片链接都是无需再进行修改,方便后续迁移.