赛博视频指北
早在一年前我做电商的时候,我就接触了AI生成,之前用来生成产品图,我个人称之为洗图,正常我从1688上采购的产品自己有图,但是那些图被很多店铺用了,一旦找下同款就很容易被找到别的便宜商家,其次是那些图片的审美更侧重实用,而不是好看。
当时我更多的是借用comfyui的工作流,我有一张产品图,想要融入我给他的另外一张背景图内,这些工作在PS上也可以完成,但是过程和复杂度很高。使用AI是一个成本和效果妥协。那时候我就已经明白文生图,还是图片修改,这些都是可以通过别的工具实现的,AI的作用是快速的实现一个效果差不多的产品,如果你对结果不是那么严苛要求的话,那么它是可以满足的。不少精益求精的商家是AI生成之后,在通过人工修改细节等问题。
我从来不相信网络上说的替代会计,替代画家,替代设计等说法,但是它是一个可以提升效率的工具,如果你的要求并不高,那么他确实解决了一些起步阶段修图工作量不大的网店痛点。这点毋庸置疑的的,阿里的店铺都是自带AI生成工具给你生成推广图的。AI的出现有点类似之前现实世界的工业革命,将高端的事物,简单化,平民化,让普通人也能成为PS高手,成为一个设计师,成为一个剪辑师,一个画家,类似软件或者说是互联网上的工业革命。
接下来说下视频,我之前还没有可以生成视频的模型,更多的是文生图,图生视频或者文生视频,只是有几个模型,不多,而且很多操作还比较复杂,后面电商做不下去了,我就没去了解,这次捡起来更多的是在JAVBUS上看到有人用AI生成的瑟瑟视频,从效果上来看,真心不错。
硬件
CPU:i5 以上即可,不是重点。
内存:32G打底,64G为佳,再往上的土豪随意,越高越好,内存在跑AI的时候会被占满,所以越大越好。
显卡:大显存的N卡,16g的最好,实在没有8g的也行。也有那种魔改矿渣22g的2080 ti,会比8g的4060ti更合适。如果你想又玩游戏偶尔跑AI的话,那还是常规款的8g版本4060ti。算力不足的话,我们可以通过时间弥补,但是显存不够的话,有些东西是没办法的,比如无法生成分辨率过大的图片,时长超过10秒的高分辨视频,然后一些效果比较好的模型无法载入等等。
硬盘:1T以上的SSD固态,最好是PCIE 4.0以上的,一个是因为那些模型文件动不动的就是20g打底,你需要很多,其次就是硬盘读取的快慢影响生成的速度,我试过机械硬盘和固态,机械硬盘的读取速度确实会成为瓶颈。
软件
当前主流模型:现在的主流的模型是wan2.2,就是阿里的模型,无论是文生视频,还是文生图,它都是有不错的效果。但是我们使用的是别人蒸馏【Distill】过的,大佬们在蒸馏的同时会附上一些自己的训练数据,使效果更符合我们的审美或者破除一些原版在瑟瑟的限制,现在比较流行的是:lightx2v和smoothmix两个魔改的模型。模型一般会附上使用说明,但是需要注意,有一些模型他没有适配comfyui的node节点,这时候要么等待大佬开发,要么可以使用命令行,一般会有py文件。
插件:comfyui是一个图形化界面,底层是python,很多模型或者操作我们还是依赖于插件,这边必须安装插件
ComfyUI-Manager,用来管理插件,你可以通过其中node安装对应插件,一般模型下面会列出工作流内使用插件。而你要做的就是通过ComfyUI-Manager进行安装。
工作流:工作流是comfyui的核心,它给予一条条工作的流程,大部分的流程都遵循着下面的逻辑:
模型——lora——clip【文本描述】——Latent ——Ksampler【采样器】——vae解码——SS输出结果
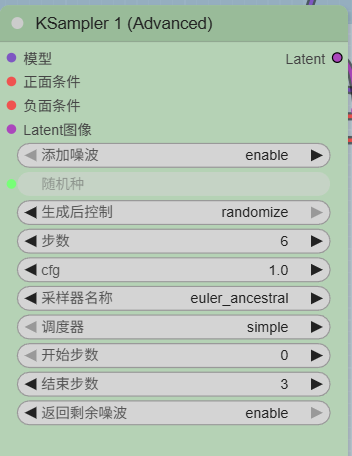
其中Ksampler【采样器】是我们的核心,你可以看到左边有四个输入,右边有一个输出,我们的目的简单说就是要将输入填满,然后拉出输出即可。
当然,如果你是纯小白,你可以使用comfyui自带的工作流模板即可,然后系统会提示你缺少哪些模型,哪些插件。你只要补足即可。
调优:经常能听见别人说的数据调优等操作,但是实际上我们能做的就是采样器上的那几个数据:步数和cfg,两者增加会使效果优化,但是过高对显卡性能要求就会比较高,高手这会通过其他插件的权重调整进行优化一些细节,包括一开始被人诟病的手,脸崩坏问题。
至此,你就对comfyui有个初步的了解,可以简单的跑跑工作流,测试一下生成的图片等等。
基础概念
这里简单描述下一些基础的概念名词:
checkpoint:就是模型,这里需要注意的,模型的大小,一般8g显存的推荐4bit-6bit的模型,在模型下载的地方他们一般会有标注,别下了太大的最后跑不起来,现阶段官方模型不会主动蒸馏的。现阶段模型一般去:https://huggingface.co/ 下载,腾讯,阿里,deepseek也在上面发布,模型会有说明的,记得看。
Lora:类似补丁,用来调整模型生成的效果,可以通过权重来微调,在初期阶段模型生成出来的图像bug太多太明显,于是就有人通过自己训练一些专门的数据,来修补这些bug,一般是手部,脸,身材之类的,这块可以去https://www.liblib.art/ 上下载,国内网站,但是商业气息很浓厚,动不动就是会员,不喜欢可以去:https://civitai.com/ 上看下,要翻墙而且很乱。我两个都不怎么用。
clip:文本,分为正向积极【positive】和反向消极【negative】,这块可以去:https://opennana.com/awesome-prompt-gallery/ 上模仿他们的文本,反向消极【negative】这块可以网络上找下,以前还需要翻译软件,现阶段的wan模型是可以直接识别中文的。
latent:我称之为空间/画布,用来配置生成的图像的分辨率,视频也是,你可以输入数值让系统自动生成空的Latent,
vae:用来编解码的,比如一张图片编码成模型认识的数据流,跑完了之后,还要解码成我们认识的图片,这种的一般都是官方模型带的,不同模型不能共用,魔改的模型用的也是官方的。
能做什么?
在简单的了解了部署和基础概念之后,我们能说下目前比较实际的东西,应用:
PS:大部分的应用工作流都可以在comfyui的[官方文档] (https://docs.comfy.org/zh-CN/tutorials/controlnet/mixing-controlnets)内找到。
- 文生图:最基础的应用,根据你的文本生成写实或者符合你审美的图片。
- 图生视频:根据一张图,生成几秒视频:本质是生成16张图片然后拼凑成16祯的小视频。
- 文生视频:这个就是生成多张图片,然后拼凑成一个视频。
- 图片修改/视频修改:允许你在图片上增加/删除文,或者进行一些其他操作。
- 3D建模:根据模型生成3D,用在游戏建模师的日常中
- 音乐生成:根据你给定的歌词+音乐风格,会生成一段音乐,效果会比较雷同,但是如果你歌词写的好,很棒的。
好了,上面是官方文档,现在说是比较实际的应用,或者我目前使用的及其效果:
- 瑟瑟:直接图片转视频,postive里面写点不可描述。有时候看见一些擦边,擦了半天让人心急燎肝的,这时候可以使用。效果一般,可以实现简单的脱衣,但是时间长度无法完成太复杂的操作,其次就是太短了,每次可以通过最后一帧图片进行下次生成,从而无限延长,但是几次之后就脸会和初始版本差距很大。
- 换脸:换脸,换衣服,换某个部分,本质是通过遮罩,重新生成某些部位,好处是最大程度的保留原视频,缺点是生成出来的东西摆脱不了遮罩的限制,比如:长裙换短裤,还是会保留长裙的一些细节特征,包括飘起来等。
进阶
在进阶之前,你要先解决一个问题:你准备用comfyui做什么?
无论你的答案是什么,我想说的是comfyui很强大,无论是换脸,换服装,换动作,还是搞瑟瑟,做电影,它都能胜任。但是方向不同导致所需要的插件也不一样,以我为例,我拿来瑟瑟之后,发现原来生成的视频分辨率为480p的,于是我找到图像放大的节点,放大,然后又找到视频合成的节点,进行二次合成,同时插帧,增加观看的舒适性。
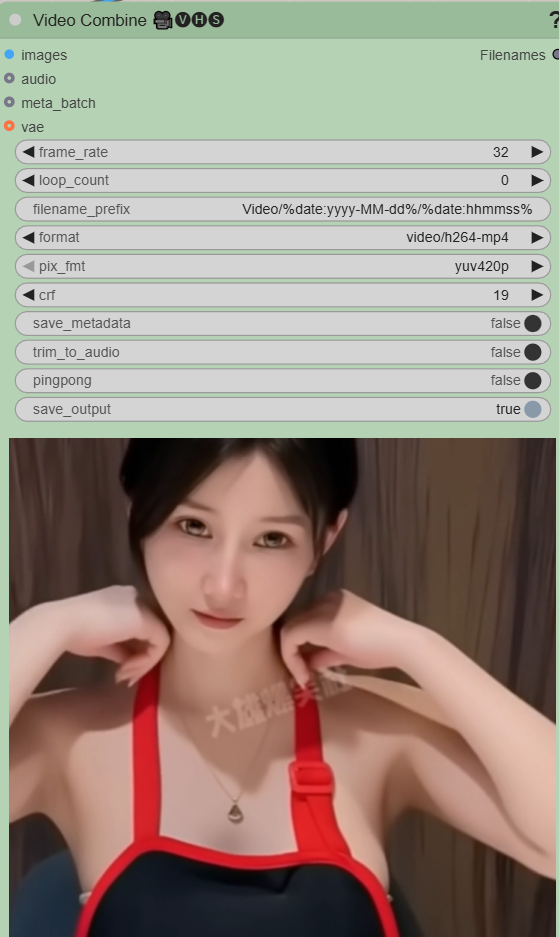
将一系列图像合并成一个输出视频。
如果提供了可选的音频输入,则音频也会合并到输出视频中。
frame_rate:每秒显示的输入帧数。帧速率越高,输出视频播放速度越快,持续时间越短。对于 AnimateDiff 节点,帧速率通常应保持在 8,或者与 Load Video 节点的 force_rate 值相匹配。
loop_count:视频需要重复播放多少次。
filename_prefix:用于输出的基本文件名。您可以将输出保存到子文件夹:subfolder/video与内置的“保存图像”节点类似,您可以添加时间戳。例如,时间戳%date:yyyy-MM-ddThh:mm:ss%可能会变成 2023-10-31T6:45:25。
format:要使用的文件格式。有关配置或添加其他视频格式的更多详细信息,请参阅“视频格式”部分。
pingpong:使输入内容反向播放,从而创建一个干净的循环。
save_output:图像应保存到输出目录还是临时目录。返回值:一个VHS_FILENAMES布尔值,指示是否启用 save_output,以及按创建顺序排列的所有已生成输出的完整文件路径列表。因此,output[1][-1]将保存最完整的输出。
根据所选格式,可能会出现其他选项,包括
crf:描述输出视频的质量。数值越低,视频质量越高,文件越大;数值越高,视频质量越低,文件越小。缩放比例因编解码器而异,但通常在 20 左右可以实现视觉上无损的输出。
save_metadata:在输出视频中包含工作流程的副本,可以通过拖放视频来加载,就像加载图像一样。
pix_fmt:更改像素数据的存储方式。yuv420p10le具有更高的色彩质量,但并非在所有设备上都有效。
根据你使用的目的不同,需寻找不同的节点工具,你学习别人的时候,更多可以看下别人怎么处理工作流的手法,毕竟核心工作流大家都是一样,细节上不同:
- 关键词的使用
- Lora权重
- 图像的放大:有多种不同的算法,也有多种不同的方式,比如VAE解码前就放大图像等等
这些方法没有最佳的,更多时候是作者经过测试,这么做生成的效果最好,在这个模型下。现阶段的AI生成更多是一个经验工程,我们需要不断的去验证试错,然后才可以找到一个满意的结果,这需要花费你大量的时间,以4060ti为例,生成一个5秒的1080p视频,我需要30分钟。如果不是相关行业或者爱好者不是很建议在上面花费大量时间,因为你调整一个参数测试下就是半小时起步,如果你有具体的需求,可以先去看看网络上有没有已经完善的工作流,然后在那个基础上进行更改。
其次,需要注意的是:由于小概率存在工作插件之间互相冲突,所以一般不是很建议你大杂烩,最好还是某个模型用的插件就不要再修改,可以复制出一份干净的comfyui便携版再去配置新的。
总结
相比较于这些概念和入门,对于我来说更重要的是,我想做什么:瑟瑟视频,还是生产力。很多时候我拿着一把马良神笔,但是不知道想要画什么,这也许就是这设计师说的没有灵感。
如果你说你目的性明确,就想要做出个什么,那么就简单了,只要学习这一条线上的知识即可,抱着目的去学习会比过来参观更加的有优势。