低显存comfyui解决思路
最近又出了一个z-imgae的大模型,听说效果很好,于是我又按耐不住的想要试试赛博找图了。
需求
这次Z-Image-Turbo的牛逼之处在于引入了一个语言翻译器,让你的文本语言可以直接的转化为图片,而不是像之前那样需要一些抽象词汇,还有反方向的提示词。但是我现在的显卡显然是不足以运行这个6B参数的模型,当然这也是很多人的苦恼,于是解决方案不外乎这几个:
- 购买api【白嫖党永不妥协】
- 云端【花钱是不可能花钱的,这辈子都不可能的】
- 使用蒸馏或者量化模型
由于我们的需求不高,而且不要求稳定性,所以最合适的还是本地使用蒸馏后的模型。
显存需求计算和蒸馏
很多时候我们不知道我们需要的显存是多少,这边简单的提供两个公式: 显存占用 ≈ 参数量 × 数据类型对应的字节数 × 系数
其中,系数在不同阶段不同:
纯推理(只有权重):系数 ≈ 1
训练(权重 + 梯度 + 优化器状态):系数 ≈ 4 - 8,甚至更高。
简单说,如果你只是拿来生成图片,而不是训练的话: 显存占用 ≈ 参数量 × 数据类型对应的字节数,首先我们来说参数里量,很多时候我们看到1B并不知道是什么意思。
| 模型参数量 | 显存估算 (仅推理,FP16) | 显存估算 (完整训练,FP16) | 适合的量化方案 (供你参考) |
|---|---|---|---|
| 1B (十亿) | 约 2 GB | 约 8 - 12 GB | 8GB显存轻松应对,几乎无需量化。 |
| 7B (七十亿) | 约 14 GB | 约 56 - 84 GB | 需要量化。4位量化后约4GB,是你8GB显存卡运行的理想选择。 |
| 13B | 约 26 GB | 约 104 - 156 GB | 需强力量化。4位量化后约7-8GB,在你的卡上运行较极限。 |
| 34B | 约 68 GB | 约 272 - 408 GB | 8GB显存无法运行,即使4位量化后也远超负载。 |
| 70B | 约 140 GB | 约 560 - 840 GB | 远超单卡能力,必须依赖多卡并行。 |
以这次Tongyi-MAI/Z-Image-Turbo为例,它是个6B模型,如果拿来生成图的话,正常是要24GB显存的,但是官方做了优化,可以轻松适应 16G 显存的消费设备,那么我们就可以根据官方默认的数据,再通过精度之间换算。
蒸馏就是将原模型的FP32的数据精度,转变位精度比较小的数值,比如BF16或者FP8,通过减少小数点后面的位数,来达到显存占用更小的目的,不同数据精度之间的换算可以大致用下表判断出来。
| 精度格式 | 比特位 | 数值范围与精度特点 | 内存占用 (相比FP32) | 主要用途与关系 |
|---|---|---|---|---|
| FP32 (float32) | 32 bit | 范围广,精度高,是深度学习的基准精度。 | 1x (基准) | 通用训练。是其他精度转换的起点和校准基准。 |
| BF16 (bfloat16) | 16 bit | 保留FP32的8位指数(范围),牺牲部分尾数(精度)。范围大,不易溢出。 | 减少 50% | 现代AI训练(主流)。与FP32范围对齐,训练更稳定,被TPU和现代GPU广泛支持。 |
| FP16 (float16) | 16 bit | 指数和尾数都比BF16小。范围小,易数值溢出(上溢/下溢)。 | 减少 50% | 训练与推理。需配合损失缩放等技术防止溢出,在特定任务和硬件上高效。 |
| FP8 (E4M3/E5M2) | 8 bit | 新兴格式,如E4M3(精度好)、E5M2(范围大)。硬件原生支持,效率高。 | 减少 75% | 未来训练与推理。在NVIDIA H100等GPU上原生支持,是下一代低精度计算的关键。 |
| INT8 | 8 bit | 表示256个离散整数。需通过量化将浮点权重映射到整数范围。 | 减少 75% | 推理加速(主流)。训练后量化 (PTQ) 的常用目标,在保持较好精度下大幅提升速度。 |
| INT4 | 4 bit | 仅16个离散值,信息损失严重,需更精细的量化算法。 | 减少 87.5% | 极致压缩推理。用于资源严格受限的场景(如你的8GB显存跑7B模型),对量化算法要求高。 |
注:更低比特的量化(如INT2、1-bit)是前沿研究,尚不成熟。
需要注意:FP32 (float32) 是基准,所以Z-Image-Turbo,在BF16这个精度下,理论上只需要8GB显存的消费级显卡即可。同样的,我们看下官方推荐的语言模型qwen_3_4b是个4B模型,在官方测试基准,使用量化BF16就是7973MB的显存,这样就可以大致确定了我们需要的显存大小了。当然这些都是拿来生成图片,如果是训练的话,所需资源就更多。
简而言之:8GB显存对应4B BF16或者8B FP8模型。你可以下载对应的蒸馏模型。
其他常见的量化技术分类和效果
目前还有其他几种用来量化方法
- GPTQ训练后量化方法,通过调整权重来节省显存。
- AWQ激活感知权重量化,既要量化,又需要精度 准确性高
- GGUF【之前叫GGML】: 基于C++,可以调用CPU进行
- QAT量化感知训练:用模型训练量化模型
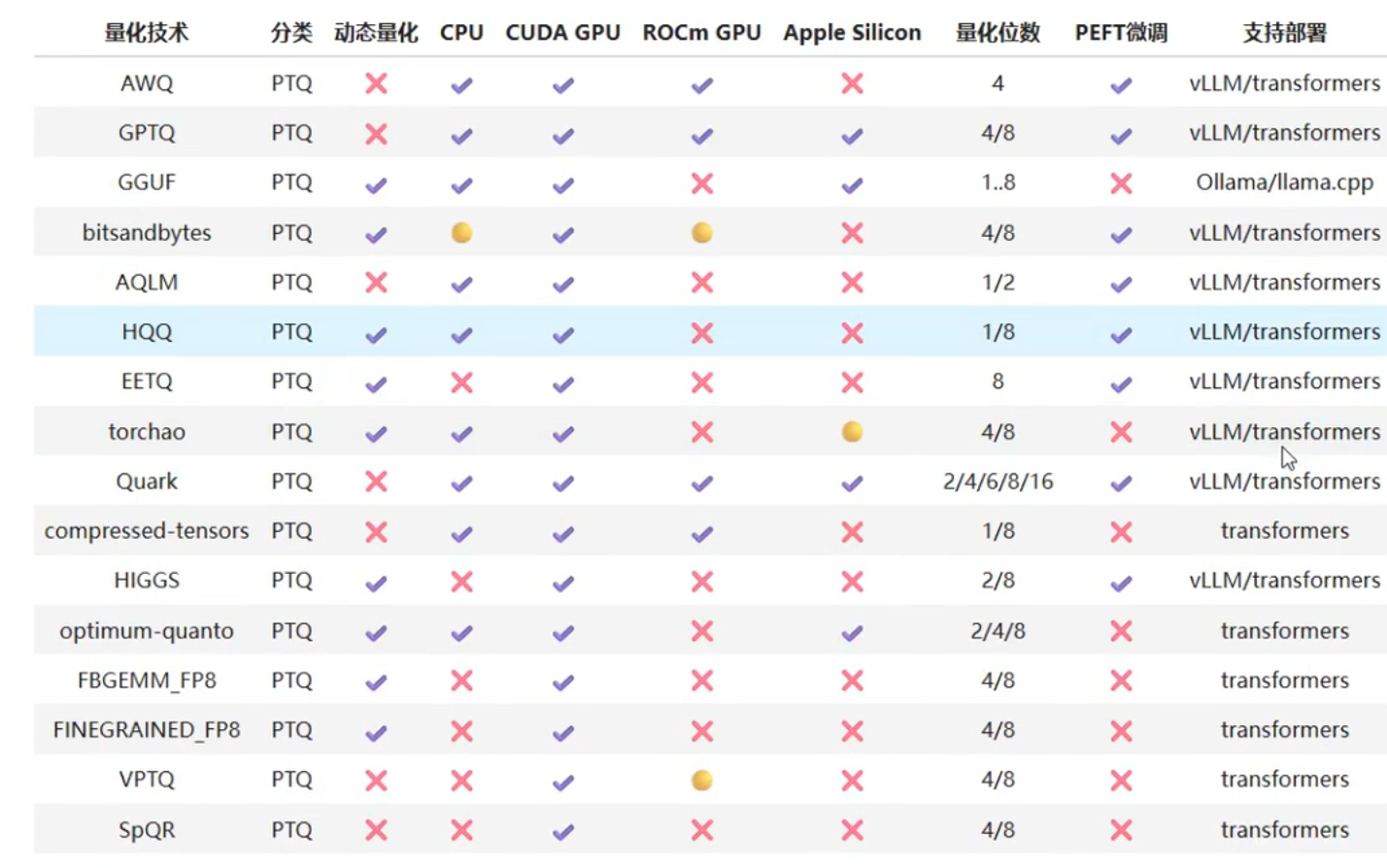
注意,这些都是量化的技术,具体节省多少内存,还想需要数据精度来确定,以GGUF为例,节省了操过一半的显存,但是效果能保持在原版的98%。
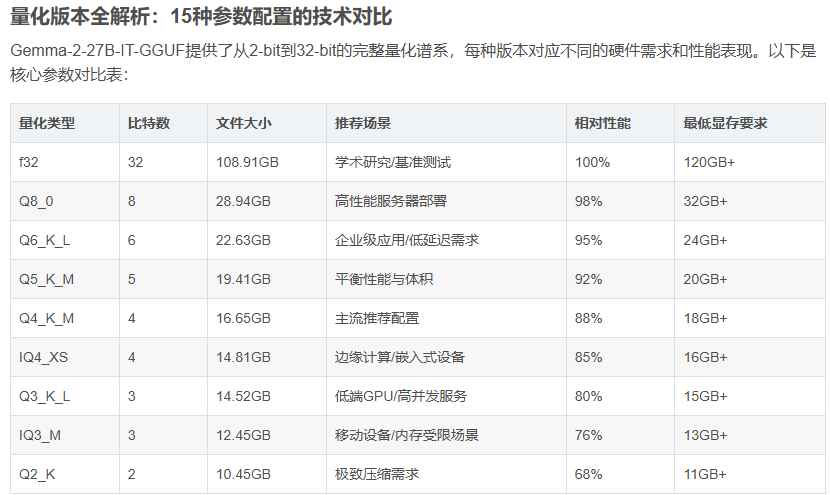
这些量化技术是不想单纯的蒸馏数据,而是希望可以通过权重,精度,系统实现等方法节省显存,本质都是修改数据精度,但是思路不同效果也就不同。
总结
由于8GB显存显卡的原因,我只能玩图生图/文生图【6秒视频81张图片差不多30分钟】,所以目前应用:
-
可以简单生成所需图片,海报,为一些文章增加点配图等,比如

我测试下来,由于QWEN的语言解释模型,现在生成出来的图片很真实,平均花费30秒每张图,而且能满足日常需求,这在我看来是趋势,包括我看到的很多视频制作者都在使用AI来提供视频素材,缩短制作时长,当然也有心怀不轨的人,会借此机会用来做一些灰色行业。后续我会试着看看能不能用它处理一些日常工作。