机器学习之路2
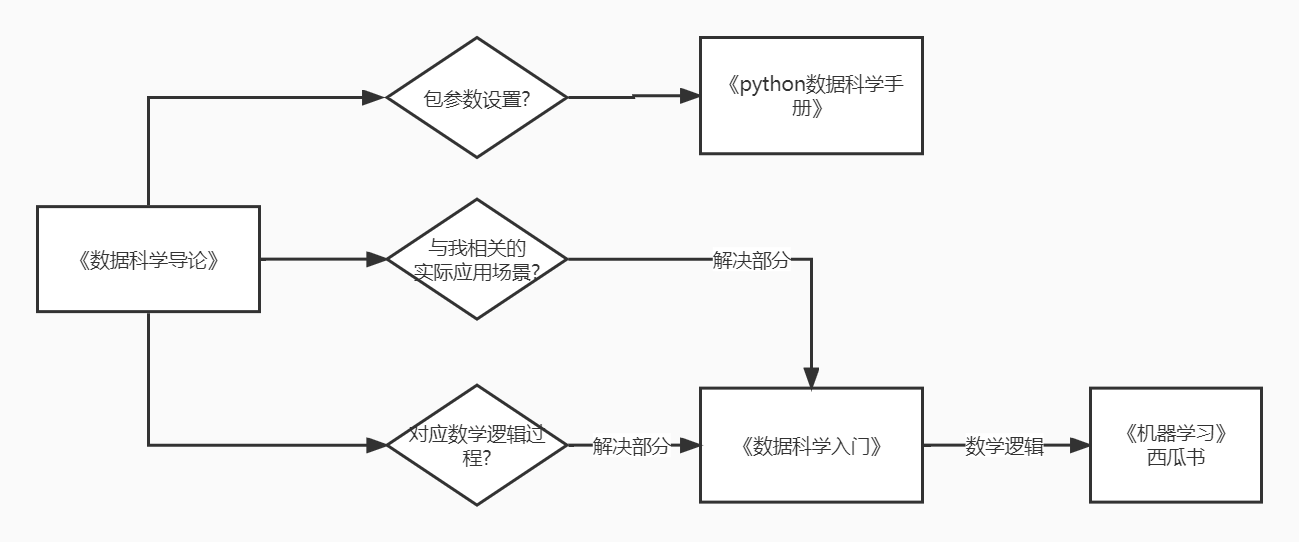
在看完《数据科学导论》之后,我选择了另外一本讲授数据科学的书:《数据科学入门》。

首先讲讲所得吧:
-
相较于导论,这本书面向的对象更多的是python的入门级选手,不仅有算法的实现,还有对一些基础知识的涉及,虽然很浅层,但是足够你理解算法。
-
书的内容很新,用到了python3来作为代码基础。
-
作者对python有深入的了解,而且自成一套体系,他写代码的过程和结果完美的遵守了这个,所以你看他的代码,如果你认真的看下去,会发现他的代码简单而有用,正如python一样。而且作者不是采用已有的库来实现各个算法,而是从头写这些算法的代码,所以深入的看完所有的代码,就好像你参与了某个开源项目一样,知道它为何这么写,以及写的原因如何。
讲完了有点,开始说说那些有所缺憾的:
-
首先还是代码,代码很精妙,也很多,但是相对于刚开始简单的算法,我们可以根据代码,反推出数学公式,或者自己了解数学公式,可以从代码中看到,但是随着算法的复杂,后面的算法代码读的越发艰难,后面几章我看到算法代码都是直接跳过。
-
很多算法都是自己手写代码,这个没问题,但是python的理念就不是重复造轮子,所以我们还需要在读一本关于这些算法已有的库的使用介绍,
-
整个阅读算法代码的感受,就好像参与一个完全开源的项目库一样,由于实现功能繁多,而且还要考虑种种情况,包括数据类型,只能说对于我这种刚入门的新手还是有点艰难,再加上有时候代码复用,看到后面我都忘记这个函数当初是为啥建立的。
-
如果可以的话,在算法实现前可以有数学算法的介绍,很多时候它介绍了算法的实现原理,但是没有数学公式推演,导致在算法代码时候看的一知半解,如果两者皆有,哪怕我只记得其中一样也可以。
后续的阅读反向估计是要先解决一下数学逻辑和库的使用,至于实际场景的应用和解析,估计要到《概率论应用》中使用,可以在看西瓜书的时候往回追溯